The art of scraping
Diego Kuperman
diegok | @freekey
Why I'm talking about this topic?
I do scrap for fun!
...and for profit!
(for +15 years)
[Supermarket]

I love the web!
(most of it)
Doing it...
And scraping it!
(kind of reverse engineering fun game)
So, what is this scrap thing!?
What do I need to know to have that fun!?
Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites. Usually, such software programs simulate human exploration of the World Wide Web by either implementing low-level Hypertext Transfer Protocol (HTTP), or embedding a fully-fledged web browser, such as Internet Explorer or Mozilla Firefox.
Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites. Usually, such software programs simulate human exploration of the World Wide Web by either implementing low-level Hypertext Transfer Protocol (HTTP), or embedding a fully-fledged web browser, such as Internet Explorer or Mozilla Firefox.
Web scraping is closely related to web indexing, which indexes information on the web using a bot or web crawler and is a universal technique adopted by most search engines. In contrast, web scraping focuses more on the transformation of unstructured data on the web, typically in HTML format, into structured data that can be stored and analyzed in a central local database or spreadsheet. Web scraping is also related to web automation, which simulates human browsing using computer software. Uses of web scraping include online price comparison, contact scraping, weather data monitoring, website change detection, research, web mashup and web data integration.
Web scraping is closely related to web indexing, which indexes information on the web using a bot or web crawler and is a universal technique adopted by most search engines. In contrast, web scraping focuses more on the transformation of unstructured data on the web, typically in HTML format, into structured data that can be stored and analyzed in a central local database or spreadsheet. Web scraping is also related to web automation, which simulates human browsing using computer software. Uses of web scraping include online price comparison, contact scraping, weather data monitoring, website change detection, research, web mashup and web data integration.
Art?
Art
- Skill acquired by experience, study, or observation
- An occupation requiring knowledge or skill
http://www.merriam-webster.com/dictionary/art
What do we need to know to have fun with this scrap thing?
- HTTP
- Simulate human exploration
- Extract information from websites
- Using a bot or web crawler
- Transformation of unestructured data
- ...
What do we need to know to have fun with this scrap thing?
- HTTP protocol
- How browsers work
- How do I write a web crawler
- How do I extract data from HTML (from any response type)
- How do web apps internals work
TOC
- HTTP protocol
- Browser basic functionality
- Tools to inspect browsing
- UserAgent libs
- DOM parsing libs
- Use it all together
- Tricks to bypass some restrictions
HTTP
0.9 (1991, informal, test drive the www)
1.0 (1996, first RFC about ^)
1.1 (RFC'd in 1997-1999, What we use today)
Do you speak HTTP?
$ telnet act.yapc.eu 80
...Request
GET /ye2015/ HTTP/1.1
Host: act.yapc.eu
Response
HTTP/1.1 200 OK
Server: Apache/1.3.42 (Unix) mod_perl/1.31
Set-Cookie: act=language&en; path=/; expires=Thu, 25-Feb-2016 16:28:37 GMT
Content-Type: text/html; charset=UTF-8
X-Cache: MISS from act.yapc.eu
Transfer-Encoding: chunked
Date: Sat, 29 Aug 2015 16:28:38 GMT
X-Varnish: 401396155
Age: 0
Via: 1.1 varnish
Connection: keep-alive
004616
<!DOCTYPE html>
...Request headers
Host:soysuper.com
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5)... (snip)
Accept:text/html,application/xhtml+xml,appli... (snip)
Accept-Encoding:gzip,deflate,sdch
Accept-Language:en-US,en;q=0.8,es;q=0.6,ca;q=0.4
Connection:keep-alive
Cookie: soysuper=eyJ3aCI... (snip)
Response headers
Connection:keep-alive
Content-Encoding:gzip
Content-Type:text/html;charset=UTF-8
Date:Fri, 07 Nov 2014 10:25:30 GMT
Keep-Alive:timeout=10
Server:nginx/1.2.3
Set-Cookie:soysuper=eyJ6aX... (snip)
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-hostname:app3.ss
The browser speaks HTTP for you
Browser 101
- DNS resolution
- Request building and send
- Response parsing and render
- Cookie jar
- Cache
- ...
Browser as a dev tool
- DOM inspector
- Network activity
- Request cycle inspection
- Request manipulation
Network activity
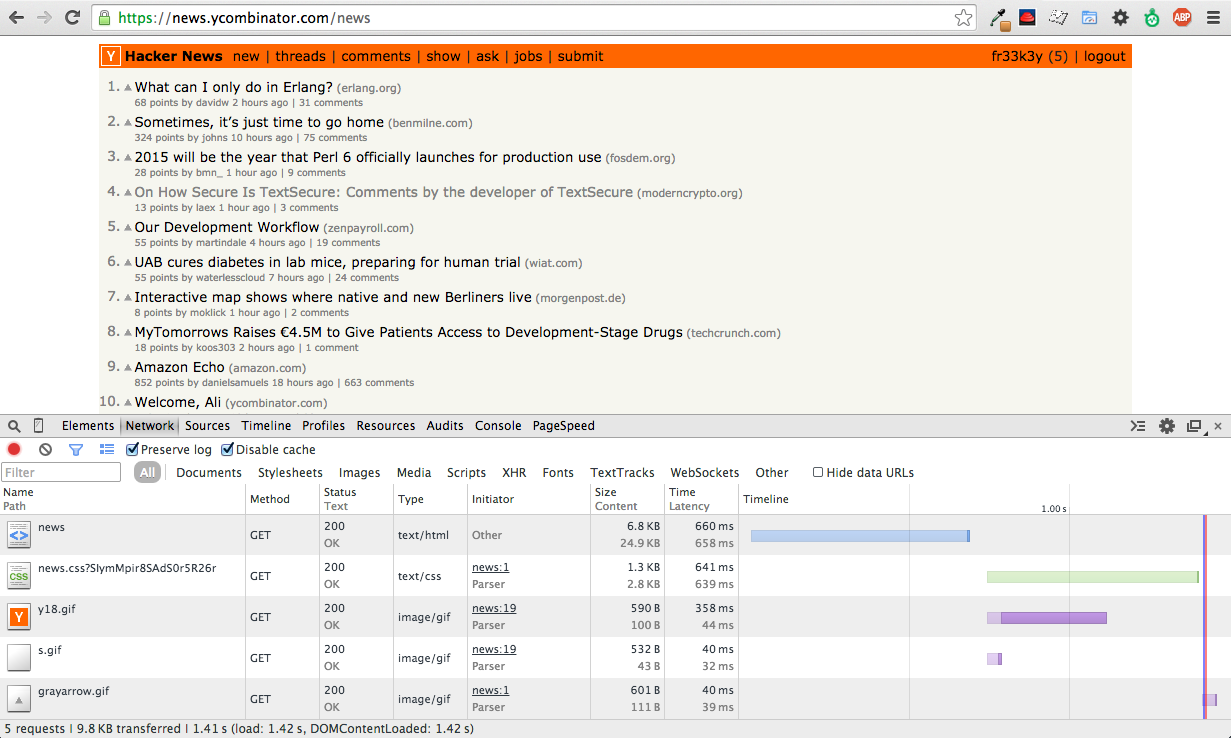
Request cycle inspector
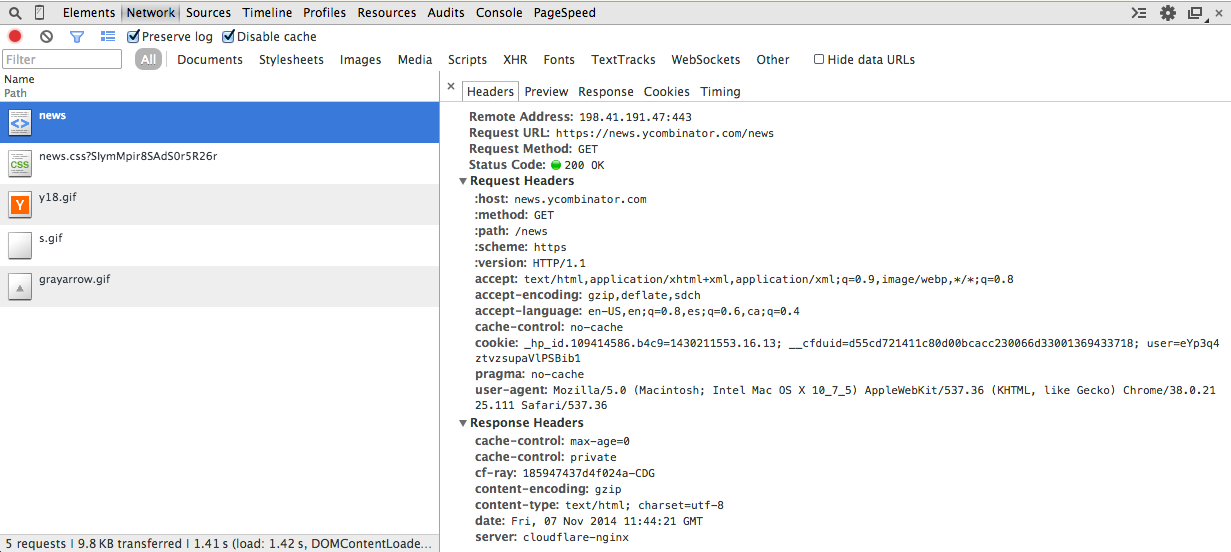
Request cycle inspector
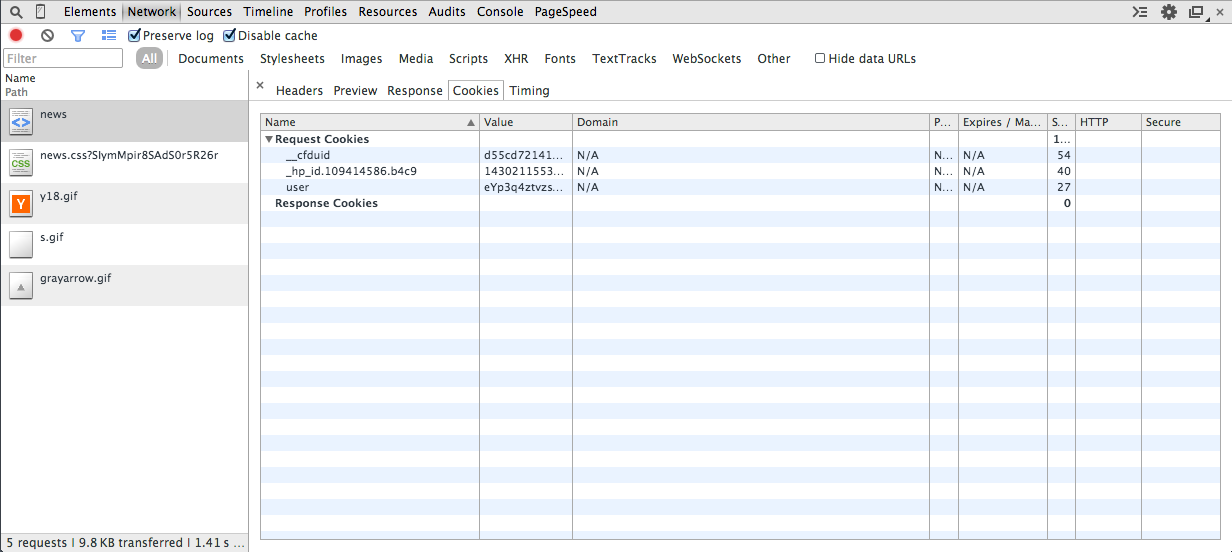
Request manipulation
Firefox Tamper Data Addon
User Agents for perl
- Control full browser
- Native perl UAs
Remote full browser
- WWW::Selenium
- WWW::Mechanize::PhantomJS
- WWW::Mechanize::Firefox (mozrepl)
Selenium web driver
use WWW::Selenium;
my $sel = WWW::Selenium->new(
host => "localhost",
port => 4444,
browser => "*iexplore",
browser_url => "http://www.google.com",
);
$sel->start;
$sel->open("http://www.google.com");
$sel->type("q", "hello world");
$sel->click("btnG");
$sel->wait_for_page_to_load(5000);
print $sel->get_title;
$sel->stop;
Screen capture
use WWW::Mechanize::PhantomJS;
my $mech = WWW::Mechanize::PhantomJS->new();
$mech->get('http://google.com');
$mech->eval_in_page('alert("Hello PhantomJS")');
my $png= $mech->content_as_png();
Native UA's
- LWP::UserAgent (libwww)
- WWW::Mechanize
- AnyEvent::HTTP
- Web::Query
- Mojo::UserAgent
- ...
Perl core
require LWP::UserAgent;
my $ua = LWP::UserAgent->new;
my $response = $ua->get('http://search.cpan.org/');
$response->is_success
? say $response->decoded_content # or whatever
: die $response->status_line;
Mech browser
use v5.10;
use WWW::Mechanize::Cached;
my $mech = WWW::Mechanize::Cached->new();
$mech->get('https://metacpan.org/');
$mech->submit_form(
form_number => 1,
fields => { q => 'diegok', },
);
$mech->follow_link( text_regex => qr/WWW::EZTV/ );
say $mech->content;
Mojo::UserAgent
Part of Mojolicious
Async suport by default
Websockets support
Mojo::UserAgent simple example
use Mojo::UserAgent;
use v5.10;
my $ua = Mojo::UserAgent->new;
say $ua->get('blogs.perl.org')->res->body;
DOM parsing and data extraction
- HTML::Parser
- HTML::TreeBuilder
- HTML::TreeBuilder::XPath
- HTML::Selector::XPath::Simple
- JSON
- ...
- Mojo::DOM & Mojo::CSS
Mojo::UserAgent data extraction (still simple)
use Mojo::UserAgent;
use v5.10;
my $ua = Mojo::UserAgent->new;
# Scrape the latest headlines from a news site with CSS selectors
say $ua->get('blogs.perl.org')
->res->dom->find('h2 > a')
->map('text')->join("\n");
JSON response
use v5.10;
use Mojo::UserAgent;
use Mojo::URL;
my $ua = Mojo::UserAgent->new;
my $api_url = Mojo::URL->new('http://api.metacpan.org/v0/release/_search');
my $res = $ua->get( $api_url->clone->query(q => 'author:DIEGOK') )->res;
say $res->json->{hits}{hits}[1]{_source}{archive};
# Mojo::JSON::Pointer (rfc6901)
say $res->json('/hits/hits/1/_source/archive');
Post
use v5.10;
use Mojo::UserAgent;
my $ua = Mojo::UserAgent->new;
$ua->max_redirects(1);
my $tx = $ua->post( 'http://domain.com/login', form => {
user => 'diegok',
pass => 's3cr3t'
});
my $tx = $ua->post( 'http://domain.com/search', json => {
query => 'something',
page => 3
});
Putting it all together
WARNING
Scraping can become adictive
Login (Post form)
use v5.10;
use Mojo::UserAgent;
use Mojo::URL;
use Data::Dump qw(pp);
my $ua = Mojo::UserAgent->new;
$ua->max_redirects(1);
my $base = Mojo::URL->new('http://act.yapc.eu/');
my $home_url = $base->clone->path('/ye2015/main');
my $login_url = $base->clone->path('/ye2015/LOGIN');
my $dom = $ua->post( $login_url, form => {
credential_0 => 'diegok',
credential_1 => 'mypass',
destination => '/ye2015/main' # hidden
})->res->dom;
die "Login error!"
unless $dom->at('.navbar-right a > .hidden-md')->all_text =~ /diegok/;
# Now we're logged in!, this is why:
say pp($ua->cookie_jar);
Building a crawler
package MyCrawler;
use Mojo::Base -base;
use Mojo::UserAgent;
use Mojo::URL;
use Time::HiRes qw( gettimeofday tv_interval );
has ua => sub {
my $self = shift;
my $ua = Mojo::UserAgent->new;
$ua->transactor->name('My Crawler 1.0');
$ua->max_redirects(3);
$ua->on( start => sub {
my ( $ua, $tx ) = @_;
my @time = gettimeofday();
$tx->on( finish => sub {
my $tx = shift;
say STDERR sprintf("%s [%s] %s (%.2f)",
$tx->req->method, $tx->res->code || 'ERR',
$tx->req->url, tv_interval(\@time)
);
});
});
return $ua;
};
Fill-in forms helper
sub submit_form {
my ( $self, $tx, $selector, $values ) = @_;
if ( my $form = $tx->res->dom->at($selector) ) {
my $url = Mojo::URL->new($form->attr('action'))->to_abs($tx->req->url);
my $method = $form->attr('method') || 'get';
my $header = { Referer => $tx->req->url.'' };
if ( $method eq 'post' ) {
return $self->ua->post( $url, $referer,
form => $self->build_params( $form, $values )
);
}
else {
return $self->ua->get( $url, $referer,
form => $self->build_params( $form, $values )
);
}
}
}
Fill-in forms helper
sub build_params_for_submit {
my ($self, $form, $fill) = ( shift, shift, shift||{} );
my $values = {};
$form->find('input')->each(sub {
if ( my $name = $_[0]->attr('name') ) {
my $type = $_[0]->attr('type') || 'text';
return if $type =~ /radio|checkbox/
&& not exists $_[0]->attr->{checked};
if ( exists $values->{ $name } ) {
if ( ref $values->{ $name } ) {
push @{$values->{ $name }}, $_[0]->attr('value');
}
else {
$values->{$name} = [ $values->{$name}, $_[0]->attr('value') ];
}
}
else {
$values->{ $name } = $_[0]->attr('value');
}
}
});
$values->{$_} = $fill->{$_} for keys %$fill;
$values;
}
Scrap this YAPC!
package ACT::YE2015;
use Mojo::Base 'MyCrawler';
use Mojo::URL;
has user => sub { die 'Need username' };
has password => sub { die 'Need password' };
has base_url => sub { Mojo::URL->new('http://act.yapc.eu') };
sub _url { shift->base_url->clone->path('/ye2015/'. shift) }
sub login {
my $self = shift;
my $tx = $self->get( $self->_url('main') );
die "Can't get login page" unless $tx->success;
my $dom = $self->post_form( 'form' => {
credential_0 => $self->user,
credential_1 => $self->password,
})->res->dom;
die "Login error!"
unless $dom->at('.navbar-right a > .hidden-md')->all_text
eq $self->user;
$self;
}
Scrap this YAPC!
sub committed_users {
my $self = shift;
my $tx = $self->get( $self->_url('stats') );
die "Can't get stats page" unless $tx->success;
my $stats = $tx->res->dom->find('.main-content p')->[0]->text;
if ( $stats =~ /(\d+) committed users/ ) {
return $1;
}
die "Can't find stats info.";
}
Scrap this YAPC!
use ACT::YE2015;
use v5.10;
my $crawler = ACT::YE2015->new(
user => 'diegok',
password => 's3cre3t'
);
say $crawler->login->committed_users; # 262
Troubleshoting guide
How to bypass some restrictions
Golden rules
- If your browser can do it...
- Look every header/cookie (I really mean every one)
- Use tamper data to simulate your crawler
- Dump headers on your crawler and compare
Browser sniffing
- Change user-agent
- ^ Simulate google bot
- Ensure header order and spacing
- Use real browser
IP banning
- TOR
- Open or paid proxies
- Get IP block + iptables
- Amazon EC2
Javascript puzzle
- Parse code and simulate
- Use real browser
- Use real browser and copy cookie-jar
Use real browser and copy cookie-jar
var page = require('webpage').create();
page.settings.resourceTimeout = 10000; // 10 secs
page.settings.userAgent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36';
page.open('https://soysuper.com', function(status) {
if (status !== "success") {
console.log("Request failed with status: " + status);
phantom.exit();
}
else {
get_cookies(page);
}
});
function get_cookies(page) {
if ( page.cookies.length ) {
console.log( JSON.stringify( page.cookies ) );
phantom.exit();
}
else {
setInterval(function() { get_cookies(page) }, 5);
}
}
Use real browser and copy cookie-jar
use v5.10;
use Mojo::UserAgent;
use Mojo::JSON qw(decode_json);
use File::Which qw(which);
my $phantomjs_bin = which('phantomjs') || die "Can't find phantomjs binary";
my $ua = Mojo::UserAgent->new;
my $cookies = decode_json(`$phantomjs_bin cookies.js`);
for my $cookie ( @$cookies ) {
$ua->cookie_jar->add(
Mojo::Cookie::Response->new(
expires => $_->{expiry},
map { $_ => $cookie->{$_} }
qw ( name value domain path secure httponly ),
)
);
}
say $_->name for @{$ua->cookie_jar->all};
Captcha
- P0rn
- MTurk
- Look for bugs